PELIKAN
Overview
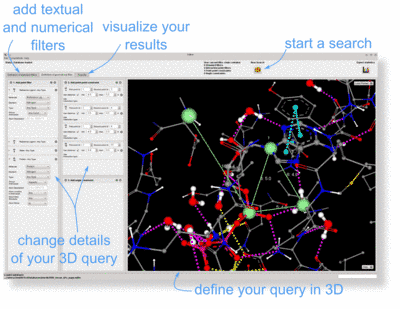
PELIKAN is a software tool enabling rapid searching of spatial interaction patterns in large collections of protein-ligand complexes[1]. Data from protein-ligand complexes is stored in an SQLite database which can be subject to different search processes.
The PELIKAN software package[1] comes with a graphical user interface, providing dialogs to build SQLite databases from any set of protein-ligand complexes and allowing the convenient construction of 3D queries starting from a protein-ligand interface of interest or from scratch. The results of a search are shown in a 3D viewer. To get a quick impression, just visit our documentation page with a few short tutorial movies.
Download
PELIKAN is a part of the AMD tools software bundle. Our software is free for evaluation purposes and academic use.
Below, precompiled PELIKAN databases containing all protein-ligand complexes of different datasets can be downloaded. Please note that these are large binary files in a propriatary database format, they can only be used with the PELIKAN software:
scPDB (version 2013, obtained from http://cheminfo.u-strasbg.fr/scPDB/) [2]. Download here (~12 GB).
Complete PDB (accessed November 2016, obtained from www.rcsb.org) [3]. Download here (~85 GB).
Kinases (kinase structures obtained from http://klifs.vu-compmedchem.nl) [4]. Download here (~5.5 GB).
GPCRs (structures of GPCRs obtained from http://gpcrdb.org) [5]. Download here (~ 210 MB).
PDB bind version 2014, general set (obtained from http://www.pdbbind-cn.org/) [6]. Download here (~11.5 GB).
PDB bind version 2014, refined set (obtained from http://www.pdbbind-cn.org/) [6]. Download here (~3.5 GB).
PDB bind version 2014, core set (obtained from http://www.pdbbind-cn.org/) [6]. Download here (~285 MB).
HIV targets (structures of reverse transcriptases, proteases and integrases obtained from https://hivdb.stanford.edu/pages/3DStructures/) [7]. Download here (~593 MB).
People and References
[1] T. Inhester, et al. (2017). Index-Based Searching of Interaction Patterns in Large Collections of Protein-Ligand Interfaces, Journal of Chemical Information and Modeling (2017) in print, DOI: http://pubs.acs.org/doi/abs/10.1021/acs.jcim.6b00561
[2] E. Kellenberger, et al. (2006). sc-PDB: an annotated database of druggable binding sites from the Protein Data Bank. Journal of Chemical Information and Modeling (2006) 46: 717-727.
[3] H.M. Berman, et al. (2000). The Protein Data Bank. Nucleic Acids Research (2000) 28: 235-242.
[4] A.J. Kooistra et al. (2016). KLIFS: a structural kinase-ligand interaction database. Nucleic Acids Research (2016) 44: D365-D371.
[5] V. Isberg, et al. (2016). GPCRdb: an information system for G protein-coupled receptors, Nucleic Acids Research (2016) 44: D356-D364,
C. Munk, et al. (2016). GPCRdb: the G protein-coupled receptor database – an introduction. Br J Pharmacol (2016), May 8.
[6] Zhihai Lui, et al. (2015). PDB-wide collection of binding data: current status of the PDBbind database. Bioinformatics (2015), 31 (3): 405-412.
[7] Soo-Yon Rhee, et al. (2003). Human immunodeficiency virus reverse transcriptase and protease sequence database. Nucleic Acids Research, 31(1), 298-303.